지난 2023년 최고의 IT트랜드는챗GPT 입니다. 그전까지는 파라미터(매개변수) 수가 적은 딥러닝의 인공지능 시대였습니다. 따라서 Chat GPT이전의 인공지능에 대한 학습을 통해 요즘의 챗GPT 4.0을 이해하면 도움이 될 수 있을 것 같습니다.(챗GPT 4.0은 파라미터 수가 1조개 이상으로 예상하고 있음)
앞으로 인공지능 기초이론을 먼저 설명하면서 차차 최근의 생성형 AI 기술도 설명해 보도록 하겠습니다.

1. 인공지능(AI) 이란
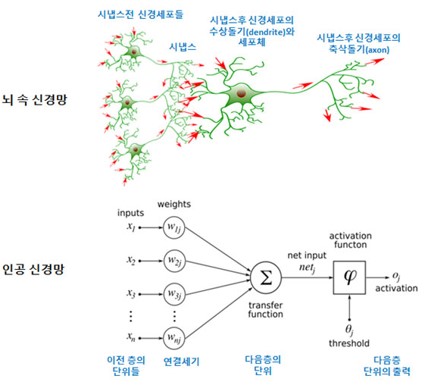
인공지능(artificial intelligence)은 인간의 지능을 모방한 컴퓨터 시스템이며, 인간의 지능을 컴퓨터 시스템에 인공적으로 구현 한 것을 말합니다. 그리고 인공신경망 인간의 뇌 구조를 모방한 기계학습 예측 모델입니다. 인공신경망은 뇌 속 신경망의 시냅스 (정보의 전달)의 결합을 모방한 인공 뉴런(노드)이 학습을 통해 연결세기(Weight)를 변화시켜 문제해결 능력을 가지는 모델 입 니다.
2. 인공지능(Artificial Intelligence), 머신러닝(Machine Learning), 딥러닝(Deep Learning)
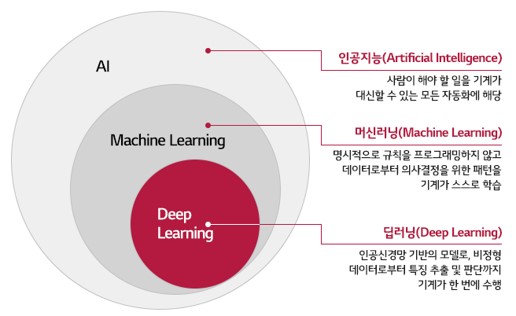
인공지능은 사람이 해야 할 일을 컴퓨터가 대신할 수 있는 모든 자동화에 해당하는 의미합니다. 그리고 머신러닝과 딥러닝의 큰차이는 머신러닝은 필요한 데이터를 미리 수동으로 만들어 놓고 학습하는 방식이고, 딥러닝은 필요한 데이터를 자율학습을 통해 찾아내는 낸다는 점입니다.
- 머신러닝은 미리 정해진 정형 데이터로 부터 의사결정을 위한 패턴을 컴퓨터 스스로 학습하는 방식
- 딥러닝은 비정형 데이터의 특징을 자율학습을 통해 스스로 추출하고 판단까지 컴퓨터가 한번에 수행하는 학습하는 방식
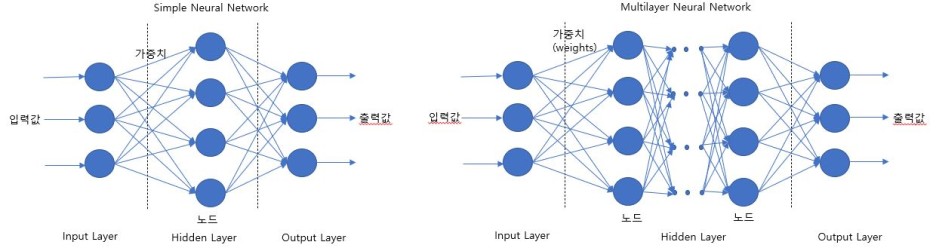
3. 인공신경망 구조
인공지능을 학습하는 구조는 3개층으로 되어 있는데 input layer, hidden layer, output layer로 되어 있습니다.
- Input layer는 데이터의 특징을 추출하여 입력하는 layer
- hidden layer는 데이터 입력값과 가중치의 합에 활성화 함수를 이용하여 출력값을 도출(Hidden Layer의 파라미터의 확대는 GPU의 성능과 HBM메모리의 성능향상이 주요 역할을 하였고, 따라서 챗GPT가 등장하게됨)
- Output layer는 도출된 결과의 패턴을 기대값과 비교하여 원하는 결과값을 출력하는 계층이다.
Hidden layer의 노드 수가 1~2개인 Simple Neural Network는 초기 머신러닝의 구조입니다. 따라서 초기 머신러닝은 학습 속도가 느리고 출력값의 정확도가 높지 않았습니다. 그러나 학습속도를 올릴 수 있는 GPU(Graphic Processing Unit)의 발전 으로 Hidden layer node수가 여러 개인 Multi Neural Network가 가능하여, 오늘날 딥러닝 학습으로 성장하게 되고 출력값의 정확도를 높일 수 있게 되었습니다.
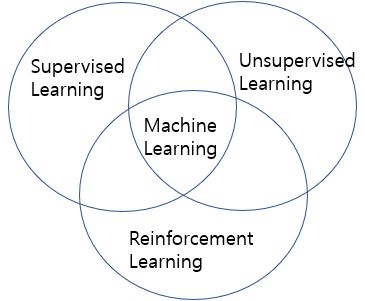
4. 머신러닝(Machine Learning) 학습방법
머신러닝 학습방법에는 지도학습(Supervised Learning), 비지도학습(Unsupervised Learning), 강화학습(Reinforcement Learning) 3가지로 분류할 수 있습니다.
1) 지도학습(Supervised Learning) 방법은 학습 데이터를 가지고 사람이 각 데이터가 가지는 출력에 대한 기대 값을 미리주고, 학습을 통해 새롭게 입력된 데이터의 결과를 알아내는 방법 -> 예측, 분류에 사용
예) 회귀분석, 로지스틱 회귀, 나이브 베이지언, KNN 의사결정 트리, Random Forest, SVM, CNN, RNN, GAN 등
2) 비지도학습(Unsupervised Learning) 방법은 사람이 답을 가려쳐 주지않고 아무런 예시없이 입력 데이터만 가지고 기계 스 스로 결과를 도출하는 방법 -> 군집화(Clustering), 연관 규칙(Association Rule)에 사용
예) 군집분석, K-means, DBSCAN 등
3) 강화학습(Reinforcement Learning) 방법은 입력 데이터를 기계가 추측하면 사람 또는 정해진 룰에서 평가 피드백(즉 보상을 통해 상은 최대화, 벌은 최소화)을 줌으로써 이를 통해 기계가 스스로 학습하는 방법 -> 보상을 통한 레벨업(Reward)에 사용
예) MDP, SARSA, Q-Learning, Policy Gradient, DQN 등
'IT' 카테고리의 다른 글
| IT 해킹시도에 대한 기업/기관의 보안대응 방안 (0) | 2024.02.10 |
|---|---|
| 애플 비전프로(증강현실 확장 MR헤드셋) 출시 (0) | 2024.02.07 |
| 큐싱 해킹공격에 대한 대응방안 (0) | 2024.02.01 |
| 생성형 AI 시대 기업의 리스킬 및 업스킬 전략 (0) | 2024.01.31 |
| IT트랜드 2024 (2) | 2024.01.28 |